[ 2024 → ATUAL ]
Accenture
Gerente SRE · Principal SRE
- Pioneiro em IA generativa no SRE — Guardrails by Design.
- Operação manual → autônoma: troubleshooting, PRR, GMUDs, IaC.
- −83% MTTR, 100% SLA/6m, −30% de cloud cost.
Gerente de SRE na Accenture e pioneiro em SRE alavancado por IA. Uso massivo de inteligência artificial na operação, construindo fluxos semiautônomos e autônomos em ambientes de missão crítica.

Eu sou a ponte: a confiança de quem já segurou o pico, com a ousadia de quem reescreve a operação com IA.
Falo, estudo e entrego com IA generativa desde antes da moda. Depois de 2 anos, vieram os números.
De analista de monitoração a Gerente de SRE. Nove anos, três grandes operações financeiras. A leitura corre pro lado →



Cortei 90% do custo de logs e 37% dos incidentes na vertical financeira. 7 anos de missão crítica.


Não é IA de slide. É uso massivo de inteligência artificial na operação real: levei o time de SRE a construir itens semiautônomos e autônomos — do troubleshooting às mudanças (GMUD, IaC, PRR).
Observabilidade e arquitetura entram com trilho, desde o primeiro commit. A IA opera com governança, não no improviso.
Agentes que diagnosticam e agem no incidente, baixando o tempo de resposta e o alert fatigue do time.
Mudanças, infraestrutura como código e Production Readiness Review com apoio de IA. Menos risco, mais velocidade.
Meu time parou de só executar tarefa. Hoje constrói skills, agentes e automações no dia a dia.
Golden Signals e telemetria padronizada com Dynatrace, OpenTelemetry e Elastic. Você vê o problema antes do cliente.
Blue-green, canary e break-glass. Sistema que aguenta o pico e se recupera sozinho, sem acordar o plantão.
Agentes e automações que tiram o trabalho repetitivo do time e encurtam o tempo de entrega.
Business case para a diretoria e corte real de desperdício em nuvem. Confiabilidade que cabe no orçamento.








300+ pessoas no KubeAuto Day SP, episódios de podcast, mentorias e o time que opera missão crítica com IA. O que vira número começa aqui — nos bastidores.
› ver no LinkedInConteúdo técnico de quem opera missão crítica todo dia — Kubernetes, FinOps, observabilidade e, principalmente, SRE alavancado por IA.
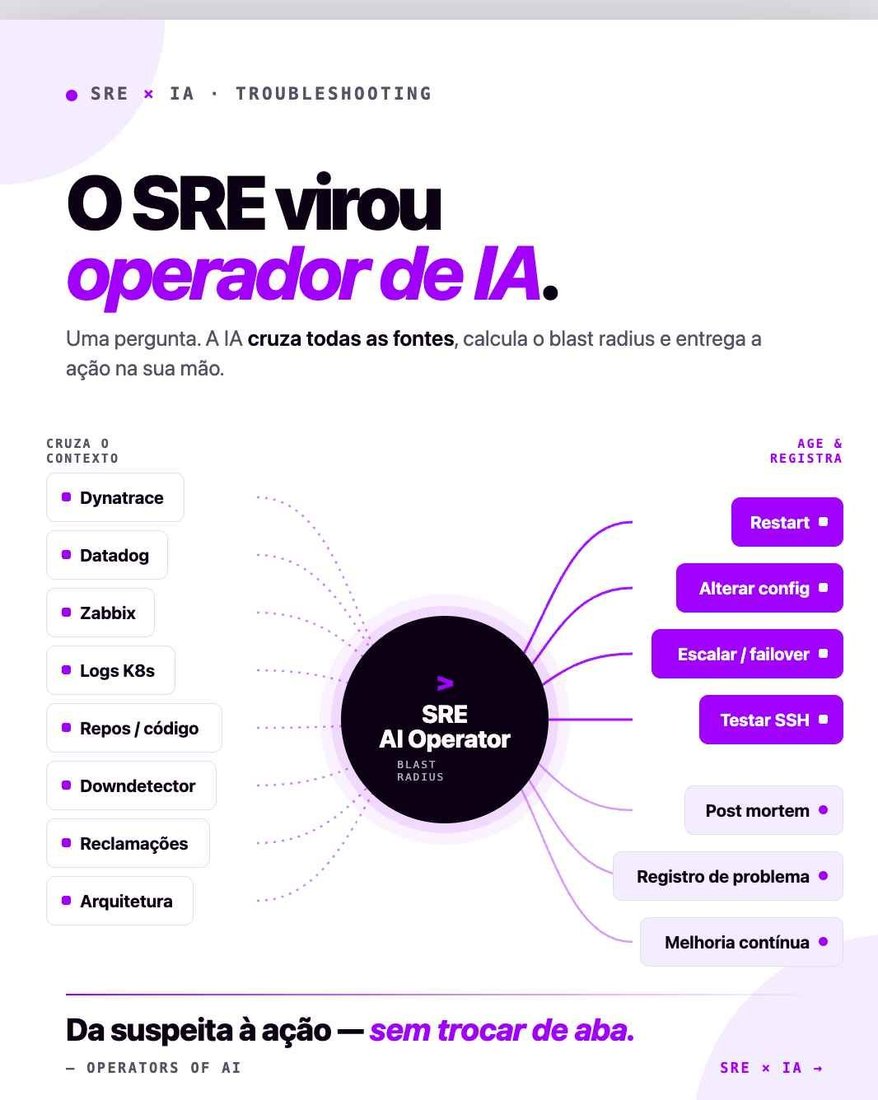
Troubleshooting deixou de ser uma caça ao tesouro entre 8 ou mais abas. Durante anos, o trabalho do SRE em um incidente foi abrir tudo ao mesmo tempo: observabilidade, logs, métricas, traces, kubectl, histórico de deploys, monitoramento externo e documentação. Depois vinha a parte mais difícil: correlacionar tudo mentalmente, sob pressão, enquanto o relógio do SLA seguia correndo. Mas esse modelo está mudando. Aqui na Accenture, tenho liderado a evolução do nosso time de SRE para um modelo onde os profissionais atuam como operadores de IA. Em vez de navegar entre dezenas de ferramentas, o SRE faz uma pergunta. O modelo correlaciona automaticamente observabilidade, topologia, deploys, incidentes anteriores, dependências técnicas e impacto funcional — e retorna o que realmente importa para a decisão: qual é o blast radius real do incidente.
ler na íntegra no LinkedIn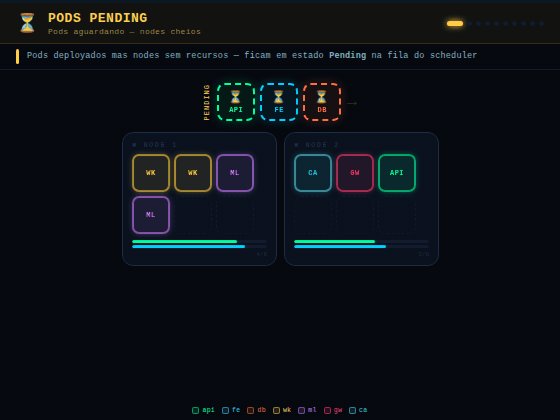
Você paga por nó, não por pod. E é aí que o FinOps em Kubernetes fica complicado. Durante o warmup ou período de carga, o HPA aumenta as réplicas. O Cluster Autoscaler provisiona nós para acomodar. A carga passa, o HPA diminui os pods. Mas os nós? Muitas vezes não diminuem junto. Basta 1 pod alocado em um nó para o Autoscaler não conseguir removê-lo. Um pod consumindo 5% da capacidade segura o nó inteiro — e você paga pelo nó cheio. E não adianta esperar o scheduler resolver sozinho: ele só age quando um pod está Pendente. O que já está em Execução, ele não toca. A fragmentação acontece em silêncio e só aparece na fatura. Bin-packing resolve: consolida os pods espalhados e libera nós que o Autoscaler finalmente consegue desligar. Fiz uma animação mostrando esse ciclo do começo ao fim.
ler na íntegra no LinkedIn
Você rodou kubectl apply agora há pouco. Mas sabe o que aconteceu nos próximos milissegundos? Não é mágica. São 11 etapas muito bem definidas, e qualquer uma delas pode ser o motivo do seu Pod não subir: 1️⃣ kubectl apply → envia o YAML ao cluster 2️⃣ API Server → única porta de entrada, valida a requisição 3️⃣ Auth → verifica quem você é 4️⃣ RBAC → verifica o que você pode fazer 5️⃣ Admission Controller → valida e muta o manifesto 6️⃣ etcd → persiste o estado desejado 7️⃣ Controller Manager → detecta que falta um Pod 8️⃣ Scheduler → escolhe o melhor Node 9️⃣ kubelet → recebe o spec e prepara o ambiente 🔟 Container Runtime → pull da imagem e start 1️⃣1️⃣ Pod RUNNING ✅ No meu dia a dia liderando SRE na Accenture, esse fluxo aparece toda semana — seja num troubleshooting de Pod preso em Pending, seja numa falha de RBAC às 3h da manhã.
ler na íntegra no LinkedIn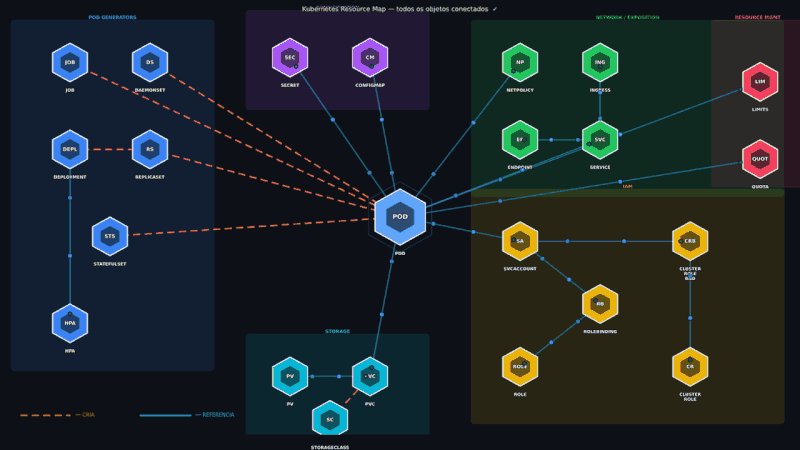
Kubernetes parece complicado? Eu entendo. Quando ouvi pela primeira vez, pareceu um bicho de 7 cabeças. 🐉 Mas deixa eu te contar um segredo: no fundo, o Kubernetes faz uma coisa só — garante que suas aplicações estejam sempre rodando, do jeito certo, na escala certa, no lugar certo. Todo o resto (Deployments, Services, ConfigMaps, Ingress, RBAC...) são peças que servem a esse único propósito. E é exatamente esse mapa de peças que eu e meu time trabalhamos todos os dias na Accenture — gerenciando clusters AKS, EKS e GKE para alguns dos maiores bancos do Brasil. 🇧🇷 Nossa rotina envolve: 📌 Garantir que os Pods sobrevivam a falhas e evições 📌 Otimizar custos com FinOps e autoscaling inteligente 📌 Manter o SLA acordado, mês após mês 📌 Construir observabilidade real, não só dashboards bonitos E sabe o que aprendi? Kubernetes não é difícil. É diferente.
ler na íntegra no LinkedIn
No último dia 27 de maio, tive o privilégio de mais uma vez levar um case da OneFinancial Accenture Brasil. Junto com meu amigo de trincheiras Ramon Maia, subimos ao palco do KubeAuto Day — o evento desembarcou no Brasil pela primeira vez, para um público de mais de 300 pessoas, e foi um sucesso. Foi um momento marcante: ver todo o meu time ali, vivenciando os aplausos daquilo que ELES fizeram. Ver o time Accenture OneFinancial, clientes participando, amigos prestigiando, reencontros e mentores. E ainda ver a Keith Fortes, minha esposa, subindo ao palco pela primeira vez, mostrando suas capacidades e entregas — para mim, não tem preço. Negócios, tecnologia e pessoas no mesmo palco.
ler na íntegra no LinkedIn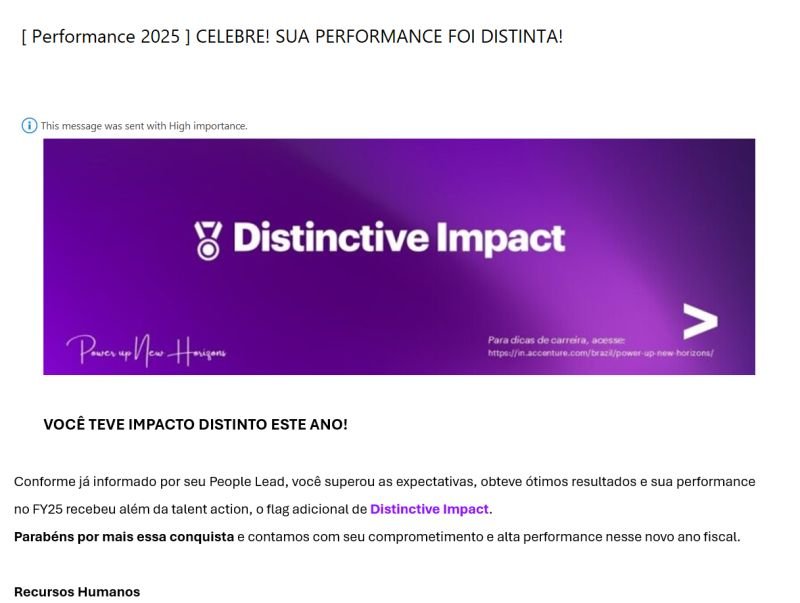
Meu primeiro ano de Accenture! E esse reconhecimento só foi possível graças ao apoio de muitas pessoas. Para não ser injusto, não vou mencionar nomes — seria impossível listar todos sem correr o risco de esquecer alguém. Aqui aprendi, mais do que nunca, que todo grande resultado é coletivo e nunca acontece sozinho. Minha missão sempre foi clara: agregar, pensar diferente, remover barreiras e dar liberdade para que as pessoas entreguem o seu melhor. Foram 12 meses de emoção, entrega e muito resultado. Obrigado, Accenture Brasil, e obrigado ao time de Financial Services, em especial ao One Financial. Vamos juntos — isso é só o começo. 🚀
ler na íntegra no LinkedIn
Falo, estudo e entrego com IA generativa desde antes da moda. Depois de 2 anos, vieram os números: −83% de MTTR e time mais produtivo.
ver no LinkedIn ↗
Madrugada virando projeto pioneiro de IA. Há 2 anos não descanso de pensar tecnologia e resolver problema com IA.
ver no LinkedIn ↗
Registrei em livro, com a Jornada Colaborativa, como se desenha confiabilidade de verdade — um tema que é paixão.
ver no LinkedIn ↗
Palestrante na Semana Acadêmica da Faculdade Rio Branco: "Desvendando a Observabilidade e a Inteligência Artificial".
ver no LinkedIn ↗
Levei a One Financial ao GTIC — Global Technology Innovation Contest da Accenture, competindo com talentos do mundo inteiro.
ver no LinkedIn ↗
Levei o case da OneFinancial Accenture ao palco do KubeAuto Day — primeira edição no Brasil. E o melhor: meu time vivendo os aplausos do que ELES construíram.
ver no LinkedIn ↗
Corte de custo com números expressivos, ligando Sustentação, Delivery e Arquitetura. Resultado que o board sente.
ver no LinkedIn ↗
No meu podcast trago referências da indústria pra mesa e abro caminho pra próxima geração de engenheiros.
ver no LinkedIn ↗
Concluí um curso de oratória. Traduzir o complexo pro board e pro palco é skill de liderança — e eu trato como tal.
ver no LinkedIn ↗Ademar é muito pró-ativo e dedicado. Está sempre disponível e disposto a ajudar. Entende, ouve, propõe, soluciona na tempestividade necessária!
Profissional de TI fora de série, com bagagem impressionante em ambientes críticos do setor financeiro. Domina a parte técnica, tem liderança inspiradora e usa IA de forma estratégica.
O tipo de profissional obcecado pela estabilidade. Na observabilidade, avalia, critica e constrói soluções que permitem atuação rápida e assertiva — e ainda forma novos profissionais.
Trabalhamos juntos no Santander por 6 anos. Combinação rara de habilidades técnicas e interpessoais: domina sistemas complexos e os comunica de forma clara.
Conhecimento robusto em ITOPS, monitoração, observabilidade, gestão de incidentes, KPIs e Tech Lead. Hoje dedicado à transformação digital e à IA.
Liderança perseverante que o levará a uma carreira meteórica. Capacidade intrínseca de liderar, adaptar-se e desatar nós com eficiência.
não renderizou? abrir em nova aba